

1. 고대 이집트인의 얼굴을 복원하다

고대 이집트인의 얼굴이 복원되었다고 한다. 2021년 9월 16일자 뉴스위크에 관련 기사가 실렸다. 미국의 파라본나놀랩은 DNA에 보관된 데이터로 사람 얼굴을 만들어냈다.
DNA 데이터는 ENA(European Nucleotide Archive)로부터 넘겨받았다. 이들은 기원전 7백년부터 5백년 전에 살았던 사람이다. DNA에는 사람의 설계도 데이터가 들어있고, 이를 해독하여 복원한 것이다. DNA 데이터 구조는 저절로 만들어진 것일까? 누군가 설계한 것일까? 이들이 미이라 형태로 발견되기는 했지만, DNA데이터가 2천년이 넘는 기간동안 보존되었다는 것도 놀랍다.
2. Human Genome Project

DNA에 담겨 있는 데이터를 읽을 수 있게 된 것은 사람게놈프로젝트 덕분이다. 1984년, 미국 정부는 사람게놈프로젝트, Human Genome Project를 발의했다. 1990년, 사람게놈프로젝트는 국제 과학연구 프로젝트로 시작되어서, 2003년에 종료되었다. 13년 동안 사람 게놈에 있는 약 32억개의 염기쌍의 서열을 밝히는데 성공했다. 사람 게놈지도가 만들어졌다. 사람 유전자 정보의 데이터 카탈로그를 만든 셈이다. 사람의 설계도를 하느님이 만들었다면, 하느님의 비밀 코드를 사람이 해킹하는데 성공한 것이다.
3. 세포, 단백질, 아미노산

사람 설계도를 만든다면 무엇에 대한 정보를 담아야 할까? 사람의 몸은 세포로 이루어져 있다. 세포를 만들면 사람이 만들어진다. 사람의 세포 수는 사람마다 다르지만, 약 30조개 이상이다. 세포의 종류는 약 200가지가 넘는다. 세포의 주 성분은 단백질이다. 사람의 단백질 종류는 수십만 종이다. 단백질은 아미노산이 결합되어서 만들어진다. 사람의 아미노산 종류는 20가지이다. 20가지의 아미노산이 단백질을 만들고, 단백질이 세포를 만들고, 세포가 사람을 만든다.
4. 테세우스의 배

약 3천3백년전 그리스 남쪽 크레타섬에는 괴물 미노타오로스가 살고 있었다. 아테네 사람들은 해마다 미노타오로스에게 산 사람을 제물로 바쳐왔다. 그리스의 영웅 테세우스는 미노타오로스를 처치하고 아테네로 돌아왔다. 그리스 사람들은 테세우스가 탔던 배를 천년 동안 보존했다. 배를 보존하기 위해서 부식된 널빤지를 뜯어내고 튼튼한 목재로 교체했다. 그렇다면 오랜 시간이 지난 뒤 많은 널빤지가 바뀐 배는 과연 테세우스의 배라고 할 수 있을까?
5. 7년마다 바뀌는 사람
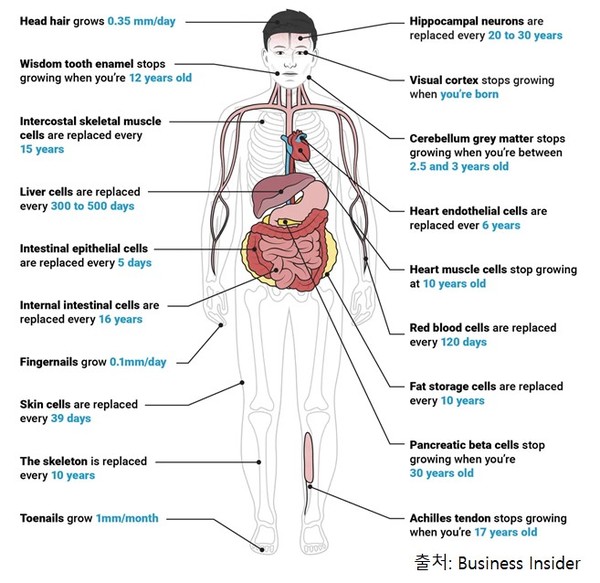
사람의 세포는 하루에 약 3천3백억개가 교체된다. 초당 380만개이다. 세포의 수명은 종류마다 다르다. 장 상피세포의 수명은 3~5일, 적혈구의 수명은 120일 정도이다. 소뇌의 뉴런, 수정체 등의 세포의 수명은 사람의 일생과 같다. 대부분의 세포는 매 7년에서 10년 사이에 교체된다고 한다. 그렇다면, 7년 뒤의 나는 지금의 나와 같은 사람일까?
세포는 사람 설계도에 의해서 만들어진다. 사람 설계도가 변하지 않는다면 같은 사람이다. 사람 설계도에 기록된 데이터가 안전하다면, 사람은 평생 같은 사람이다.
6. 염색체, DNA, 유전자

사람 설계도는 세포의 핵 안에 존재하는 염색체에 보관되어 있다. 사람의 염색체는 23쌍으로 되어 있다. 염색체는 실타래처럼 생겼다. 실타래의 실이 바로 DNA이다.
DNA는 두 가닥의 실이 나선형으로 꼬여 있는 사다리 모양이다. 두 가닥은 수많은 계단으로 연결되어 있다. 이 계단을 염기쌍이라고 한다. 염기쌍 전체를 게놈이라고 한다.
사람의 게놈은 약 30억개의 염기쌍으로 이루어져 있다. 게놈 전부에 유전 정보가 기록되는 것은 아니다. 유전 정보가 위치한 부위는 따로 있는데, 이를 유전자라고 한다.
사람의 유전자 수는 약 2만에서 2만5천개이다.
7. 데이터 물리적 구조

하나의 세포 핵 안에 있는 DNA를 모두 연결하면 길이는 약 2미터나 된다. 한 사람의 세포 수는 30조개 이상인데, 모든 세포에는 DNA가 들어가 있다. 전체 세포 안에 들어가 있는 DNA를 모두 연결하면 그 길이는 60조미터 이상이다. 지구와 화성을 60번 이상 왕복할 수 있는 길이라고 한다. DNA는 두 가닥이 서로 꼬여 있는 형태로 되어 있다. 왜 두 가닥일까?
첫째. 데이터를 보다 안전하게 보관할 수 있다. 백본에 의해서 보호된다. DNA데이터를 외부 영향으로부터 보호하기 쉽다.
둘째, 데이터 손상이 있을 때 복구할 수 있다. 다른 쪽 가닥의 데이터를 활용하면 된다. DNA 데이터가 잘못되면 발생할 수 있는 질병을 방지할 수 있다.
셋째, 데이터를 보다 빠르게 읽을 수 있다. 두 가닥을 풀면 데이터를 동시에 읽을 수 있다. 이는 생명을 유지하기에 필요한 단백질을 늦지 않게 만들도록 한다.
8. 데이터 보관 장소

DNA는 엑손과 인트론으로 구분된다. 실제 유전자는 엑손에 존재하고, 인트론에는 존재하지 않는다. 엑손은 전체 DNA의 2%에 불과하다. DNA의 98%는 유전자가 없는 것이다. 실제로 유전자 정보를 활용하여 단백질을 만드는 과정에서 인트론은 사용되지 않는다. 그래서 인트론은 정크 DNA로 불리기도 한다. 하지만 분명 역할은 있을 것이다. 엑손을 보호하기 위해 필요하다는 설도 있다. 믿거나 말거나 한 이야기지만, 사람의 일생을 기록하는 치부책이라는 설도 있다. 심판의 날, 하느님이 그 사람을 판단하는데 사용된다는 것이다.
9. 데이터 체계

DNA를 구성하는 단위는 염기이다. 염기는 네 가지가 있다. 염기가 네 가지라는 것은 유전자의 데이터는 4진법이라는 뜻이다. DNA에 연속된 세 개의 염기를 트리플렛코드라고 한다. 하나의 트리플렛코드를 읽으면 하나의 코돈이 된다. 하나의 코돈에 담긴 데이터를 적용하면 하나의 아미노산이 된다. 이는 사람이 만든 컴퓨터의 비트, 바이트와 비교된다. 하나의 비트는 0과 1 두가지 상태를 가질 수 있다. 2진법이다. 하나의 바이트는 8개의 비트로 구성된다. 2의 8승 256가지를 표현할 수 있다. 하나의 바이트는 하나의 문자와 대응된다.
10. 데이터 응용

하나의 염기는, A(아데닌), T(티민), G(구아닌), C(사이토신)의 네 가지 상태를 가질 수 있다. 4진법이다. 하나의 트리플렛 코드는 3개의 염기로 구성된다. 4의 3승, 64가지를 표현할 수 있다. 하나의 트리플렛 코드는 하나의 아미노산과 대응된다. 사람의 아미노산은 20가지이므로 트리플렛 코드로 충분히 표현할 수 있다. 4진법은 2진법과 비교하면, 처리 속도와 공간 효율성 등이 뛰어나다. 미래의 기술인 양자컴퓨팅에서는 큐비트를 사용한다. 큐비트 하나는 네가지 상태를 표현할 수 있다. 양자 컴퓨팅이 활성화되면 사람의 컴퓨터가 하느님의 데이터 처리능력을 갖는 셈이다.
11. 데이터 복구

사람이 만든 컴퓨터 시스템의 데이터 오류율이 백분율로 한 자릿수 이상이다. 정교하게 만들어진 DNA체계이지만, 여기에도 오류가 발생한다. 사람의 몸에는 이러한 오류에 대비하기 위한 시스템이 준비되어 있다. 오류는 DNA복제 과정에서, 외부의 원자력이나 자외선 노출 등에 의해서 발생한다. DNA오류의 탐지와 복구에는 DNA에 보관된 상대 가닥의 데이터가 활용된다. 컴퓨터 시스템으로 치면 백업 데이터인 셈이다. 차이가 있다면 유전자 데이터는 염기 단위로 즉, 컴퓨터로 치면 비트 단위로 백업을 유지한다는 점이다. 그리고, 유전자 데이터 체계는 이를 이용하여 데이터 손상이 발생하더라도 즉시 그리고 완전하게 데이터를 복구할 수 있다. 그 결과로 사람의 몸에서 발생하는 DNA 데이터 오류는 식스시그마 수준 이하라고 한다.
12. 데이터 수명 관리

텔로미어는 염색체의 양 끝 부분이다. 텔로미어는 유전정보가 들어있는 DNA가 손상되지 않도록 보호하는 역할을 한다. 세포 분열이 이루어지면, 텔로미어의 길이는 짧아진다. 분열이 계속되어 텔로미어가 닳아 없어지면, 세포는 더 이상 분열하지 못한다. 텔로미어의 길이가 짧아지는 것이 노화 현상이다. 텔로미어는 유전자의 생명주기를 관리한다. 컴퓨터 시스템의 데이터도 생명주기 관리가 필요하다. 데이터는 일정 기간이 지나면 더 이상 유효하지 않거나 쓸모없게 된다. 주소 데이터는 1년이 지나면 30% 정도가 틀린 데이터가 된다. 데이터를 활용할 때 이 데이터가 언제 생성되었는지 알아야 하는 이유이다. 유전자 데이터는 염색체 단위로 생명주기가 관리된다. 컴퓨터 시스템의 데이터의 생명주기는 타임스탬프로 관리된다.
13. 안젤리나 효과

안젤리나 졸리의 어머니는 난소암으로 세상을 떠났다. 이모는 유방암에 걸렸다. 안젤리나 졸리는 자신의 유전자 검사를 받았다. 브라카 유전자에 돌연변이가 있다는 검사 결과가 나왔다. 브라카 유전자는 DNA 손상을 복구하는 기능을 한다. 브라카 유전자에 이상이 생기면 유방암 또는 난소암에 걸릴 위험이 높아진다고 한다. 2013년, 안젤리나 졸리는 난소와 유방을 제거하는 수술을 했다. 이후, 유전자 돌연변이 검사 건수가 크게 증가했고, 이를 안젤리나 효과라고 한다. 유전자 데이터의 위치에 따른 기능을 알고 있으면, 유전자 데이터를 활용할 수 있다. 유전자 데이터의 위치와 기능은 유전자 데이터 카탈로그이다. 데이터 활용의 기본은 데이터 카탈로그를 확보하는 것이다.
14. DNA Storage

DNA의 데이터 저장 기술을 응용하기 위한 시도가 데이터스토리지이다. DNA활용 방식은 집적도가 매우 뛰어나다. DNA 활용 방식은 또한 데이터 보관 기간이 매우 길다.
지금까지 만들어진 모든 영화를 DNA스토리지에 보관할 경우, 스토리지의 크기는 각설탕 하나보다 작을 것이라고 한다. 또한 DNA스토리지에 보관된 데이터는 10,000년 정도는 지속될 것이라고 한다. 2017년 마이크로소프트는 DNA기술을 이용한 저장장치를 개발했다고 밝혔다. 그리고 10년 안에 데이터 센터 내 DNA기반의 운영 스토리지를 갖추는 목표를 공식화했다. DNA는 물리법칙에 기초한 우주에서 가장 밀도높은 저장장치라고 관련자는 설명했다. 하지만 현재는 비용이 비싸다. DNA스토리지 생산 원가가 1만분의 1 정도로 떨어져야 경제성이 있다고 한다. 속도 개선도 해결과제이다.
15. 모더나 백신

코로나바이러스 백신 제조사는 유전자 데이터 체계를 성공적으로 활용하고 있다. 모더나는 mRNA 플랫폼을 만들고 있다. mRNA는 메신저RNA로서 DNA데이터를 아미노산 제조공정으로 전송하는 기능을 한다. mRNA 플랫폼은 컴퓨터의 OS, 운영체계와 매우 유사하다. DNA는 데이터 저장소이다. mRNA는 소프트웨어로서, 일종의 API이다.
아미노산으로 만들어지는 단백질은 응용시스템, 즉 애플리케이션이다. 모더나는 이러한 플랫폼을 만들기 위해 수백명의 과학자와 엔지니어로 구성된 전담 팀을 운영하고 있다.
16. 마치면서
사람이 만든 컴퓨터의 데이터 체계와 유전자 데이터 체계는 유사점이 많다. 비트와 바이트, 염기와 코돈. 메신저RNA와 API 등은 비슷하다. 하지만 데이터 복구 자생력, 데이터 집적도, 데이터 속도, 데이터 내구성 등은 유전자 데이터체계가 훨씬 뛰어나다. 유전자 데이터 체계는 어떻게 만들어졌을까? 놀라운 것은 유전자 데이터 체계는 모든 생물이 같다는 점이다. 진화에 의해서 자연적으로 만들어지는 것이 가능할까? 만약, 하느님이 만든 것이라면, 하느님은 가장, 엄청, 뛰어난 데이터아키텍트임이 분명하다.
