
AutoML 모델링 과정
AutoML은 인공지능 개발 과정 중 어느 곳에 사용되기에 보조적 수단인 것일까? 그것을 알아보기 위해 인공지능을 모델링하는 일반적인 과정을 알아보자.

[An overview of AutoML pipeline, AutoML: A Survey of the State-of-the-Art, Hong Kong Baptist University, 2019.08]
1. 데이터 수집(Data Collection)
모델링에 필요한 각종 데이터를 DB 또는 API 등을 통해 수집함
2. 데이터 전처리(Data Cleaning)
수집한 데이터에 Label을 추가하거나, 결측치, 이상치 제거 등 훈련용 데이터로 사용하기 위해 정제함
3. 변수 개발(Feature Construction)
데이터 기존 변수들의 조합, 변형 등 조작을 통해 새로운 변수를 개발함
4. 변수 선택(Feature Selection)
전체 변수 중 모델에 투입될 변수를 선별함
5. 모델 선택(Model Selection), 아키텍처 탐색(Architecture Searching)
모델링에 사용할 GBM, Deep Learning 등 알고리즘을 선택하여 훈련함
6. 초매개변수 최적화(Hyperparameter Optimization; HPO)
초기 모델의 구조를 변경 및 설정할 수 있는 설정값의 최적값을 찾아 맞춰 나감
7. 모델 평가(Model Evaluation)
모델의 예측력, 인식력 등의 성능지표를 평가하고 검증함
이 모든 프로세스를 수행하는 것은 상당한 시간과 노력이 든다. 각 단계에서 다양한 가설 수립과 추측, 직관적 선택이 필요하며 마지막 단계인 성능 테스트를 통해 그 가설에 의해 생성된 데이터 변수들과 선택한 모델의 초매개변수들이 성능에 좋은 영향을 미치는지 검증한다.
첫 번째 테스트 결과가 나왔다면 이 성능을 개선하기 위하여 적용했던 가설과 조건들을 조금씩 변경하면서 계속해서 전체과정을 반복한다. 따라서, 이전 프로세스로의 회귀가 여러 번 반복됨에 따라 적용할 수 있는 경우의 수는 수없이 많다.
이 모든 과정을 한정적인 시간 내에 진행해야 하므로 테스트할 조건의 범위가 제한된다. 신경망 알고리즘의 경우 한 번 테스트하는데 하루가 넘는 경우도 많기 때문에 더욱 신중한 조건 범위 설정이 필요하다. 이러한 머신러닝 개발을 과정은 다양한 조건으로 실험하고 검증하는 과학실험과 유사하여 ‘데이터 과학(Data Science)’이라고 불린다.
AutoML은 앞서 설명한 모델링 과정에 다양한 조건으로 진행하는 실험적 행위와 시행착오를 대신 수행하는 도구로서, 인공지능이 인공지능 전문가를 대체하는 것이 아닌 일부 과정에 사용되는 자동화 도구이다. 인공지능 전문가 또는 데이터 과학자가 탐색적 데이터 분석(EDA)이나 변수 개발, 커뮤니케이션 등 창의적이며 생산적인 활동에 집중할 수 있도록 도움을 준다. 이것은 마치 요리사가 다른 활동에 집중할 수 있는 시간을 벌기 위해서 믹서기를 사용해 온갖 재료들을 한순간에 갈아버리는 것과 같다.

[What is Automated Machine Learning? Microsoft Azure docs]
AutoML 사용 예시로 변수, 알고리즘, 초매개변수, 3가지 영역에 대해 후보변수가 3개, 후보 알고리즘이 2개, 후보 알고리즘은 파라미터 1개를 가지며 그 파라미터는 옵션값이 3개가 있다고 가정해보자. 우리는 AutoML 결과 페이지에서 총 36가지(3! * 2 * 3 = 36) 모델을 확인할 수 있을 것이다. 각 모델의 성능 결과를 볼 수 있고, 이 중 제일 성능이 높은 모델에는 어떤 변수들, 알고리즘, 초매개변수가 적용됐는지 확인할 수 있을 것이다.
AutoML의 적용 범위
AutoML은 전체 모델링 프로세스에 적용될 수 있지만 좋은 효과를 내는 것은 두 가지로 추려진다. ‘초매개변수 최적화’와 ‘모델 선택/아키텍처 탐색’이다.
1) 초매개변수 최적화(Hyperparameter Optimization)
초매개변수 최적화란 모델의 튜닝옵션을 학습을 통해 추정하고 가장 좋은 설정값을 찾아내는 것을 의미한다. 일반적으로 인공지능 모델 당 초매개변수는 수십 또는 수백 개를 가질 수 있으며, 각각의 초매개변수의 타입별로 연속형(Continuous), 정수형(Integer), 또는 범주형(Categorical)의 형태로 그 종류가 다양하여 시도 가능한 경우의 수는 셀 수 없다.
기존에는 전문가의 직관에 의해 큰 영향을 주는 초매개변수 들을 하나하나 값을 바꾸고, 모델을 학습시키고, 이전 모델의 결과에서 깨달은 바를 바탕으로 조금 바꿔서 시도하는 것을 반복했다.
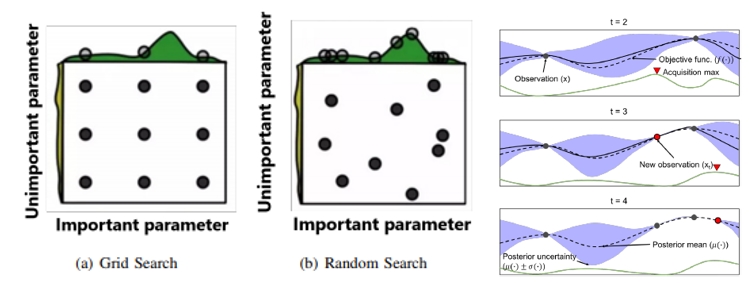
하지만 이제는 AutoML에서 초매개변수를 추정하는 그리드 서치(Grid Search), 랜덤 서치(Random Search), 베이지안 최적화(Bayesian Optimization) 방법 등을 사용할 수 있어 시행착오에 소모되는 시간을 줄일 수 있게 됐다.
[“Random search for hyper-parameter optimization”, Bergstra & Bengio, JMLR 2012(좌), [A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning,”arXivBrochu et al, 2010(우)]
그리드 서치란 적용 가능한 경우의 수를 나열하여 앞에서부터 순차적으로 진행하는 것이다. 이 방법은 모든 경우를 테스트해 본다는 것에서 의미가 있지만 모델의 알고리즘이 복잡해질수록 적용 가능한 초매개변수의 조합의 수와 학습시간은 무한대에 가깝다.
또한 초매개변수의 간격을 얼마로 하냐에 따라 최적값을 지나칠 수도 있다. 이에 대한 방안으로 랜덤 서치를 사용할 수 있는데 이 방법은 말 그대로 아무런 조합을 시도해 보면서 그 중의 최적값을 찾아가는 방법이다.
의외로 이 방법은 초매개변수들이 많아져도 학습 시간과 성능에서 우수한 면을 보여 많이 사용하게 되었다. 베이지안 최적화 방법은 기존에 추출되어 평가된 결과를 바탕으로, 다음에 실험할 조건의 추출 범위를 좁혀서 효율적으로 시행하는 것이다. 이 방법은 Bayesian theory 및 Gaussian process에 접목하여 개발된 것으로, 시간 대비 성능이 매우 탁월하여 유명 기계학습 플랫폼에서 주력으로 삼고 있는 기술이다.
2) 모델 선택/아키텍처 탐색(Model Selection & Architecture Searching)
모델 선택/아키텍처 탐색 단계에선 데이터의 유형에 따라 분석하고자 하는 적합한 알고리즘과 방식을 선택하게 된다. 데이터의 유형은 크게 정형 데이터와 비정형 데이터로 구분할 수 있으며, 일반적으로 정형 데이터에 대해선 Random Forest, Gradient Boosting Machine 같은 트리 기반의 알고리즘이, 비정형 데이터에 대해선 Convolutional Neural Network, Recurrent Neural Networks와 같은 신경망 기반의 알고리즘이 주로 사용된다. 따라서, AutoML에 사용하는 데이터 유형에 따라 정형 데이터일 때는 모델 선택 방식이, 비정형 데이터일때는 아키텍처 탐색 방식이 사용된다.
최근 AutoML은 신경망 기반의 NAS에 대한 연구가 좋은 성능을 보인다. NAS는 Neural Architecture Search의 준말로써 최근 AutoML은 NAS를 중심으로 많은 논문이 게재되고 있으며, 성능개선이 이뤄지고 있다. 글로벌 기업에선 구글과 아마존, 국내 기업에선 네이버와 카카오 등 유명 IT기업 인공지능 연구팀의 AutoML 논문이 계속해서 발표되고 있다.
앞서 설명한 초매개변수 최적화가 설정값들을 변경하는 것이라면, NAS는 모델의 구조 자체를 변경하는 Search Space에 관한 것이다. 올해 이 분야에서 대표 논문 중 하나인 DARTS(Differentiable Architecture Search)를 예를 들면, 후보 아키텍처 공간이 연속적이라고 가정하여 Gradient(경사 하강) 접근법 적용을 가능하게 함으로써 기존의 블랙박스 탐색보다 훨씬 효율적으로 탐색할 수 있게 되었다.
이미지 인식 분야에서 AutoML의 NAS는 사람의 수준보다 성능과 개발 속도 면에서 뛰어나기 때문에, 이른 시일 내 수작업으로 만드는 네트워크 디자인이 필요 없을 수 있게 될 수도 있다.

[Hanxiao Liu et al, “An overview of DARTS”, DARTS, 2019.02]
대표적인 AutoML 솔루션
AutoML은 오픈소스 프로젝트, 상업용 소프트웨어 및 API의 형태로 상당수의 공급자가 서비스를 제공하고 있다. 유명 솔루션 일부를 소개한다.
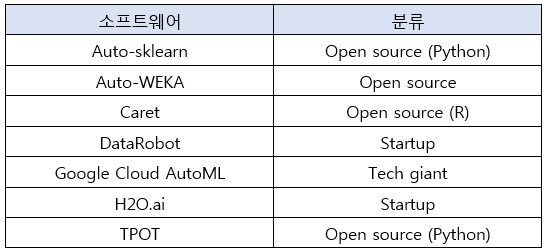
[“AutoML Software / Tools in 2019: In-depth Guide”, AI Multiple(수정 발췌)]
AutoML의 사상이 누구나 쉽게 사용하도록 하는 것이기 때문에 대부분의 솔루션은 간단한 방식으로 AutoML을 체험해 볼 수 있다. R 또는 Python을 사용할 줄 안다면 Auto-sklearn, Carat, H2O.ai 등 튜토리얼 코드를 참고할 것을 추천한다.
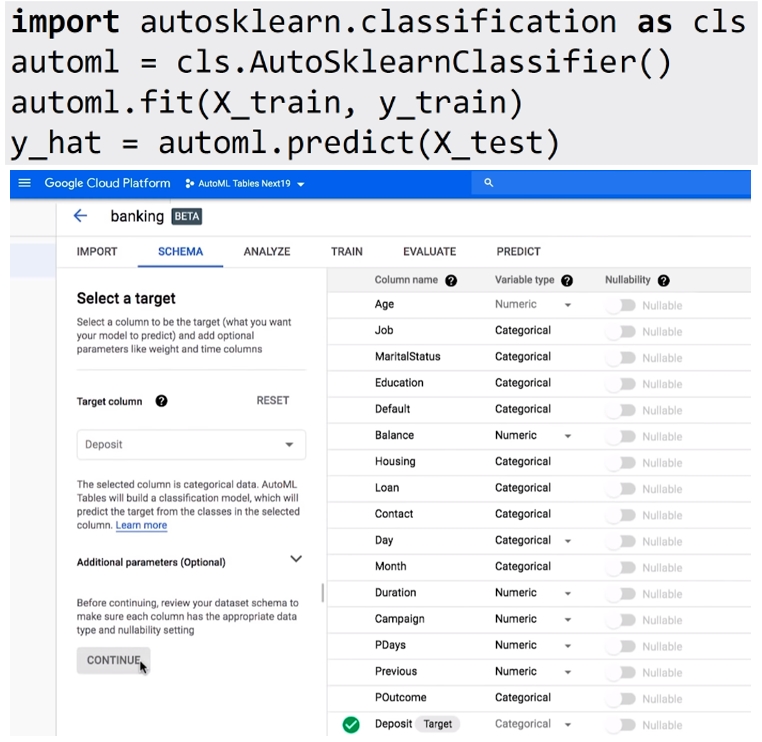
[단 4줄의 코드로 구현 가능한 Auto-sklearn의 예시 코드(상)와 웹 UI에서 실행되는 Google AutoML Tables 예시 화면(하)]
코드를 다루기 어렵다면 Google에서 제공하는 코드 없이 웹 UI에서 클릭만으로 개발할 수 있는 상용 서비스를 무료로 체험해 볼 수 있다. Google에서는 정형 데이터를 처리할 수 있는 Google Cloud AutoML Tables와 비정형 데이터 처리, 특히 이미지 인식에 특화된 Google Cloud AutoML Vision 서비스를 제공한다.
마치면서
두 편의 에세이를 통해 AutoML 정의와 적용 범위, 핵심 기법과 대표적인 솔루션에 대해 알아보았다. 전문지식이 없는 일반인이라도 머신러닝을 개발할 수 있도록 한다는 AutoML의 ‘머신러닝 대중화’를 향한 야망은 현재 진행 중이다. 머신러닝 개발과정의 복잡한 것까지 알고 있지 않더라도 단순한 코드 몇 줄 또는 클릭 몇 번 만으로 인공지능 개발이 가능함으로 수고를 덜어주고 진입장벽을 낮춰주었다.
AutoML 덕분에 머신러닝의 진보 속도는 더욱 빨라질 것이다. AutoML이 개발과정의 소모적인 부분을 담당하고 전문가는 창의적이고 생산적인 영역에 역량을 집중할 수 있게 되면서 인공지능 기반의 서비스의 전반적인 품질 향상이 기대된다. 향후 AutoML이 지속해서 발전을 이룬다면 정말 모든 모델링 프로세스에 완전하게 적용될 수 있는 End-to-End AutoML의 시대가 올지도 모를 일이다.
- 끝 -
