비밀번호를 잊어 로그인 반복 시도 시 마주하게 되는 난관이 있다. 잔뜩 꼬여있거나 흐리거나 글자 크기가 모두 달라 구분하기 어려운 글자 입력 요청, CAPTCHA다. CAPTCHA가 무엇이며 종종 CAPTCHA가 요청되는 이유는 무엇인지 알아본다.
캡차 원리
CAPTCHA는 Completely Automated Public Turing test to tell Computers and Humans Apart로 컴퓨터와 인간을 구분하기 위한 완전히 자동화된 공개 튜링 테스트의 약자다. 2000년 카네기 멜론 대학에서 처음 만들어졌다. 튜링테스트는 인간의 행동을 모방하는 컴퓨터의 수준을 평가하는 테스트다. 컴퓨터가 인간의 행동을 정확히 따라하면 테스트를 통과할 수 있다. CHPTCHA가 튜링테스트의 약자지만, CHPTCHA는 컴퓨터가 모방할 수 없는 사람의 행동을 판단하는 것이기 때문에 엄밀히 말하면 튜링 테스트와는 다르다. 컴퓨터에게 ‘인간을 따라해봐’라고 문제를 내는 것이 아니라, 사람에게 ‘네가 사람인지 증명해봐’라는 방식으로 문제를 내는 것이다.
해커는 맞는 비밀번호를 찾을 때까지 숫자, 문자, 특수 문자까지의 조합을 생성하는 봇을 만들어 무작위 대입 공격으로 사용자 계정에 로그인해 계정 정보를 탈취하곤 하는데, 반복 로그인 실패 이후 CAPTCHA를 풀도록 하면 이런 공격을 중단시킬 수 있게 된다. 온라인 여론 조사와 같이 기계의 반복을 통해 조작이 가능하거나, 콘서트 티켓 반복 구매 등을 방지하기 위해서 사용될 수 있다.
캡차 발전
초기 CAPTCHA는 컴퓨터가 왜곡된 글씨를 읽는 능력이 사람보다 떨어지는 것에서 착안해 만들어졌다. 글자가 겹쳐져있거나, 블러 처리되어있는 글씨를 읽는 등 컴퓨터가 작업하기 어려운 일을 해내는 것이다. 당시 자동화 프로그램이 캡차를 해독할 확률은 1% 이하로 알려져 있었다.

사람과 컴퓨터를 구분하기 위해 만들어진 CAPTCHA 코드지만, 요즘엔 사람도 풀기 어려운 CAPTCHA가 등장하는 경우가 종종 있다. 사람들이 풀어낸 CAPTCHA가 기술 발전에 사용되었기에 발생한 역설이다. 구글은 오래된 책의 디지털화와 AI 발전에 CAPTCHA를 활용했다. 얼룩이 있거나, 글씨의 왜곡이 있어 컴퓨터 스캐너는 읽지 못했으나 사용자는 읽어낼 수 있는 단어를 CAPTCHA에 활용한 것이다. 입력값과 출력값이 매칭된 데이터의 축적으로, 컴퓨터 문자 인식 기능이 발전했고, 컴퓨터는 일부 CAPTCHA를 풀 수 있게 되었다. 자연히 CAPTCHA 코드도 점점 어려워져야 했다.
이미지 인식 방식의 CAPTCHA 해석이 점점 더 어려워지자, 접근성 문제도 대두되었는데 노화, 장애 등으로 시각에 문제가 있는 경우의 사용자 경험이 고려되지 않았기 때문이다. 이에 따라 이미지 인식뿐만 아니라, 오디오 인식, 퍼즐, 그리고 마우스 드래그 및 드롭핑을 활용하는 등 상호작용이 필요한 CAPTCHA가 만들어졌다. 컴퓨터는 일반적으로 동일하게 반복되는 상황에서의 처리는 잘 하지만, 다양한 상황에서 처리를 어려워하기 때문에 이런 방식을 취한 것이다. 같은 카페 사진이어도 비가 오는 날, 눈이 오는 날, 다른 각도에서 찍은 경우 모두 다르게 판단할 수 있기 때문이다. 현재는 약 100여개의 CHAPTHA 종류가 있을 것이라고 한다.
이미지 식별 형태의 CAPTCHA 배포는 AI의 이미지 인식/처리 수준을 높였다. AI이미지 처리 수준을 높이기 위해서는 문제와 답이 정해진 데이터 세트가 많을수록 좋은데, 사람이 풀어낸 CAPTCHA 문제와 답을 활용하는 것이다. 구글에 따르면 하루에 사람들이 풀어내는 CAPTHA는 2억 개라고 한다. 2억개의 데이터가 매일 추가되는 방식으로 이미지 인식 AI기술이 발전한 것이다.향상된 봇은 왜곡된 글자를 인식하고, 퍼즐을 풀었으며, 인간의 행동을 따라했다.
이에 따라 관련 연구진은 CAPTCHA 작동 방식을 재조정하는 연구를 진행했다. 행동분석학자들은 로봇 행동과 인간 행동의 차이에 집중했고 사람의 특성을 활용해 생체인증을 더하는 방안을 고안했다. 2014년 Google이 도입한 노캡차 리캡차(No CAPTCHA reCAPTCHA)는 대표적인 행동 기반 CAPTCHA도구다. 기기에 접근할 때 사용하는 사용자 생체인증을 활용하거나, 사용자가 웹 페이지를 사용하는 행동 양식을 검사해서 유효성을 검사한다고 한다.
노캡차는 클릭 한 번으로 사람과 컴퓨터를 구별하는 테스트다. ‘로봇이 아닙니다.’ 옆 체크박스를 선택하는 단순한 확인이 어떻게 보안 기능을 하는지 궁금했을 것이다.

사용자의 커서가 체크박스에 다가가는 동안의 동작을 확인하는 방식이다. 사람이라면 체크박스로 바로 커서를 이동시킨다고 해도, 작은 수준에서 어느정도 무작위한 움직임을 보이는데 컴퓨터는 이런 무작위성을 보이지 않기 때문에 사용자가 사람임을 판단할 수 있는 것이다.
무작위성이 크게 보이지 않는다고 판단하면 노캡차 방식 이후 또 다른 방식의 CAPTCHA(reCAPTCHA)를 통해 사람임을 재확인한다. 재확인을 진행하며 사용자 기기의 브라우저에 저장된 쿠키나 기기 이력을 추가 활용해 사용자가 봇일 가능성을 판단한다고 한다.
캡차의 종말?
이런 캡차의 종말이 다가왔다는 말이 있다. CAPTCHA를 활용한 보안의 효과성이 낮아지고 있고, 범죄 형태의 변화와 AI의 발전 때문입니다.
범죄 집단은 인건비가 낮은 국가에서 사람을 고용해 직접 CAPTCHA를 풀게하거나 CAPTCHA를 아예 풀지 않는 우회적인 방식으로 접근하고 있다고 한다.
또한 생성형 AI의 발전도 CAPTCHA무효화를 가속화하고 있다. 생성형 AI 이전의 AI 발전이 빠르게 진행되기는 했지만, AI 기술 접근성이 높지 않았기 때문에 범죄자 집단에서 AI를 활용한 봇을 만들어 CAPTCHA를 풀기엔 비용 효익이 낮다고 판단해왔다. 그러나 생성형 AI는 모두를 대상으로 AI 기술 접근성을 낮췄다.
현재의 생성형 AI 모델은 이미지, 오디오 형태를 인식할 수 있는데, 오픈AI에서 개발한 GPT-4V는 글자 찾기, 다른 이미지 찾기 문제를 80% 성공률로 풀 수 있었다고 한다.
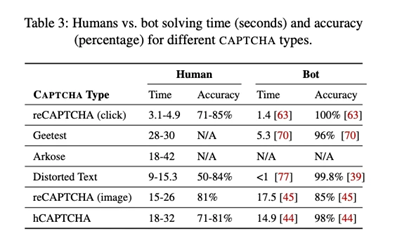
마이크로소프트, 캘리포니아 대학 협동 연구팀이 수행한 연구 결과에서도 AI봇이 사람보다 최대 15% 높은 정확도로 CAPTCHA를 풀었다. 사람이 50-85%범위에서 문제를 풀때, 봇은 85-100%의 정확도 범위를 보였다. 문제를 푼 시간은 사람과 비슷하거나 적었다. 튜링테스트 관점에서, 현재 컴퓨터는 85%-100% 정도로 인간의 행동을 모방할 수 있는 것이다.
AI 기술에 대응할 수 있는 CAPTCHA 발전뿐 아니라 CAPTCHA와 함께 사용되어야 하는 추가 보안 설정이 필요한 시점이다. 앞으로 CAPTCHA는 우리에게 또 어떤 문제를 제시할까. 기존 CAPTCHA를 보완할 다음 보안 형태는 어떤 모습일까. 기술의 발전을 또 다른 기술로 막아야 하는 창과 방패의 싸움. 앞으로의 싸움을 지켜보자.
참고
1. CAPTCHA: The story behind those squiggly computer letters (phys.org) https://phys.org/news/2012-06-captcha-story-squiggly-letters.html
2. The End of CAPTCHA? Testing GPT-4V and AI Solvers vs. CAPTCHA | CHEQ https://cheq.ai/blog/testing-ai-gpt-4v-against-captcha/
3. Artificial intelligence smart enough to fool Captcha security check https://www.bbc.com/news/technology-41775968
4. CAPTCHA란? https://www.ibm.com/kr-ko/topics/captcha
